アカツキインターンに行ってきて考えたこと
株式会社アカツキさんにてありがたいことにインターンをさせていただきました。
きっかけ
直接的なきっかけとしては Supporterz の 1on1 で人事の方とお話させていただいたことです。
ただそれまでにも、大学のZliサークルで開催した企業さんとの合同LT会や、前の年の1on1イベントなどで何度かお話させていただいたこともあり採用に力を入れている企業さんだなという認識はありました。ただゲーム系の企業は今のところどこもRails/Unityの人材を探している印象が強く、あまり興味を持って話を聞いたことがありませんでした。
しかし去年の夏にnatumnくんがアカツキのATLASチームというところでインターンをした話を聞き、「なんだかGoでゲーム基盤を開発しているらしい」「とても働きやすい環境らしい」という印象を持ちました。
そこで1on1で人事の花田さんとお話した際にインターンをお願いし、2月の12日から3月1日まで受け入れていただくことになりました。
したこと
配属していただいたのはnatumnくんと同じATLASチームです。
主に課金基盤アプリケーションのカナリアリリース周りを触っていました。
Go1.11.4対応/調査
やっていた期間: 2 / 12 - 2 / 13
これはもともとIssueとしてあったタスクではなく、環境構築中に手元でアプリケーションのビルドができなかったことからIssueを作ったものです。
エラー内容からどうやらいくつかのダウンロードしたGoのモジュールがgo.sumに記述されたチェックサムに適合していない、というもののようでした。
go: verifying github.com/aktsk/nolmandy@v0.1.2: checksum mismatch
go.sumを削除すれば正常にビルドできることから、該当のモジュールにForce Pushやタグの付け替えがありチェックサムが変更された可能性をまず考えましたが、そのような心当たりはないという話を聞き、頭をひねっていたところ
cmd/go: symbolic links not dropped from repo [1.11 backport] · Issue #29191 · golang/go
このようなIssueを見つけ、「Go1.11.4からシンボリックリンクを含むモジュールのチェックサムが変わった」ことがわかりました。
というわけで開発者間で使用するGoのバージョンを合わせる必要が出てきたわけですが、ここで疑問としてでてきたのが「GAEでGo1.11.4以降のgo.sumを使用できるのか?」ということでした。これができればローカルでの開発でもGo1.11.4以降を使用できますし、そうでなければローカルも古いバージョンにとどめておく必要があります。
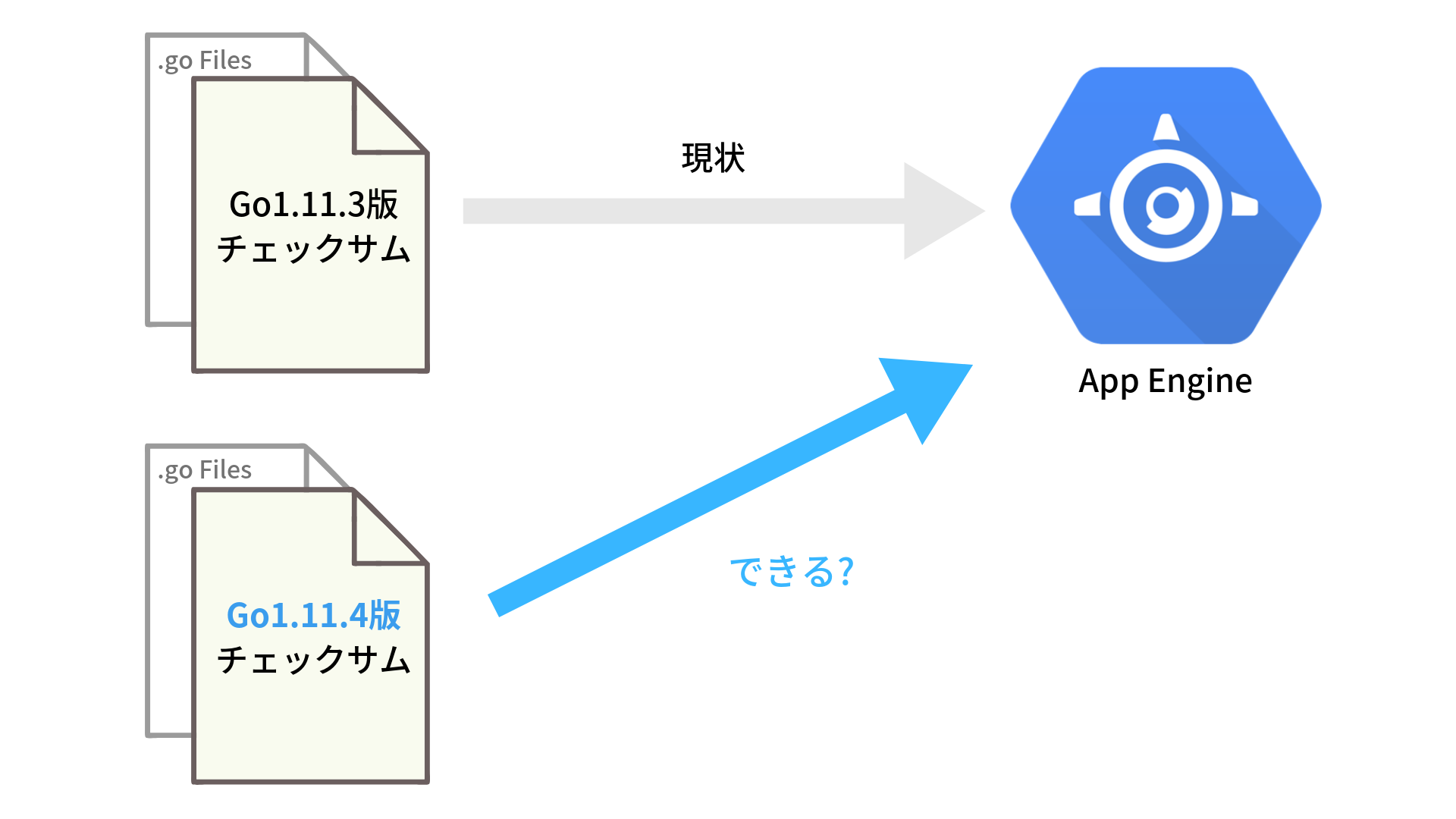
この調査が主な初仕事となりました。ドキュメントにめぼしい記述1がなかったため実際にデプロイを試してみた結果、同様のエラーがCloud Build上で発生し、Go1.11.4以降のgo.sumは使用できないことがわかりました。2
このときは以下のアクションを取るべきとし、Issueを閉じました。
- ローカルではGo1.11.3を使用し、go.sumもそれに合ったものにする
- GAEがGo1.11.4以降に上がったタイミングでgo.sumもアップデートする
ドキュメントにはgo111ランタイムがどのマイナーバージョンのGoを使用するかまでは明記されていない3ため、GAEがGo1.11.4以降にバージョンアップしたと(何らかの方法で)わかったタイミングで改めてgo.sumを変更する必要がありました。
とりあえずこれで一旦は解決したと思い次の日から次のタスクに入ったのですが、実は自分たちの環境ではその日からGoのバージョンが上がったり下がったりを始め、最終的にgo.sumをしばらく削除するという結論になりました。ずいぶんGAEに振り回されたしょっぱなだったなと思います。
多段カナリアリリース
やっていた期間: 2 / 14 - 2 / 19
課金基盤アプリケーションではカナリアリリースを採用しています(こんな感じでやっています: GAE/Go & CircleCI でカナリアリリースをする - Akatsuki Hackers Lab | 株式会社アカツキ(Akatsuki Inc.))。自分が入社したときはデプロイ対象にプロダクションの1%のトラフィックを流し、問題がなければ100%に切り替えるというオペレーションをしていたのですが、1%のカナリアリリースだけではアプリケーションの以下のような問題を取りこぼす可能性がありました。
- 特定の順番でリクエストが来た場合にのみ起こるエラーなど、複合的な要因のもの
- CPU使用率が高いなど、高トラフィックの環境でしか観測できないもの
現状の1%のカナリアリリースの他に、10%と50%のリリースステップを追加することでこれらの問題が発生したときにいち早く認識できるのではないか、ということで「カナリアリリースの多段化」が2つ目のタスクとなりました。

CTOの田中さんのメモ。それぞれの段階が必要な理由が言語化されていたのでやりやすかった。
取り掛かる前はすぐ終わるだろうと思っていましたが、実際やってみるといろいろと必要な知識があり時間がかかりました。
- Bash(あまり書いたことがなかった)
- CircleCIのOrbs/Commands/Jobsについて
またCircleCI2.1の設定ファイルにCircleCI CLIが対応しておらずローカルでのテストができなかったことや、最終的にはもともとそこそこ大きいCircleCIの設定ファイル(YAML)に更に200行以上追加するパッチとなってしまい、大きい設定ファイルを整合性を保ちながら注意深く修正するのがとても大変だったりしました。
カナリアリリース中に特定のAPIが叩かれたかどうかレポートするシステム(Ensurerun)
やっていた期間: 2 / 19 - 3 / 1
1on1で「次なにやりたい?」と聞かれた自分は「どうせなら最後までCI周りやります」ということで、タイトルのようなタスクを選ばせていただきました(この時期からアプリケーションのドメイン知識を仕入れるとちょっと時間の無駄になってしまいそうだったのと、大きいアプリケーションのCI周りなら個人開発では学べないことを学べるだろうという判断でした)。
前タスクで多段化されたカナリアリリースですが、「いつ次のリリースステップに上げる(つまり1%→10%にするなど)か」というのは人が判断していて「ある程度時間が経って問題がなさそうだったら次のステップに上げる」というフローを踏んでいました。
この方法はとてもシンプルゆえ、デプロイ周りを複雑化させないという点において理想的な方法でしたが、「どのくらいの時間が経ったらいいのか」という部分が定量化しにくく、地道にログをみて変更箇所が動いているか確認したり、「そろそろいいだろう」という感覚だよりの部分もありました。
この状態を改善する方法として、「指定したAPIエンドポイントが一定回数成功したら通知する」アプリケーションを作成することが考えられました。
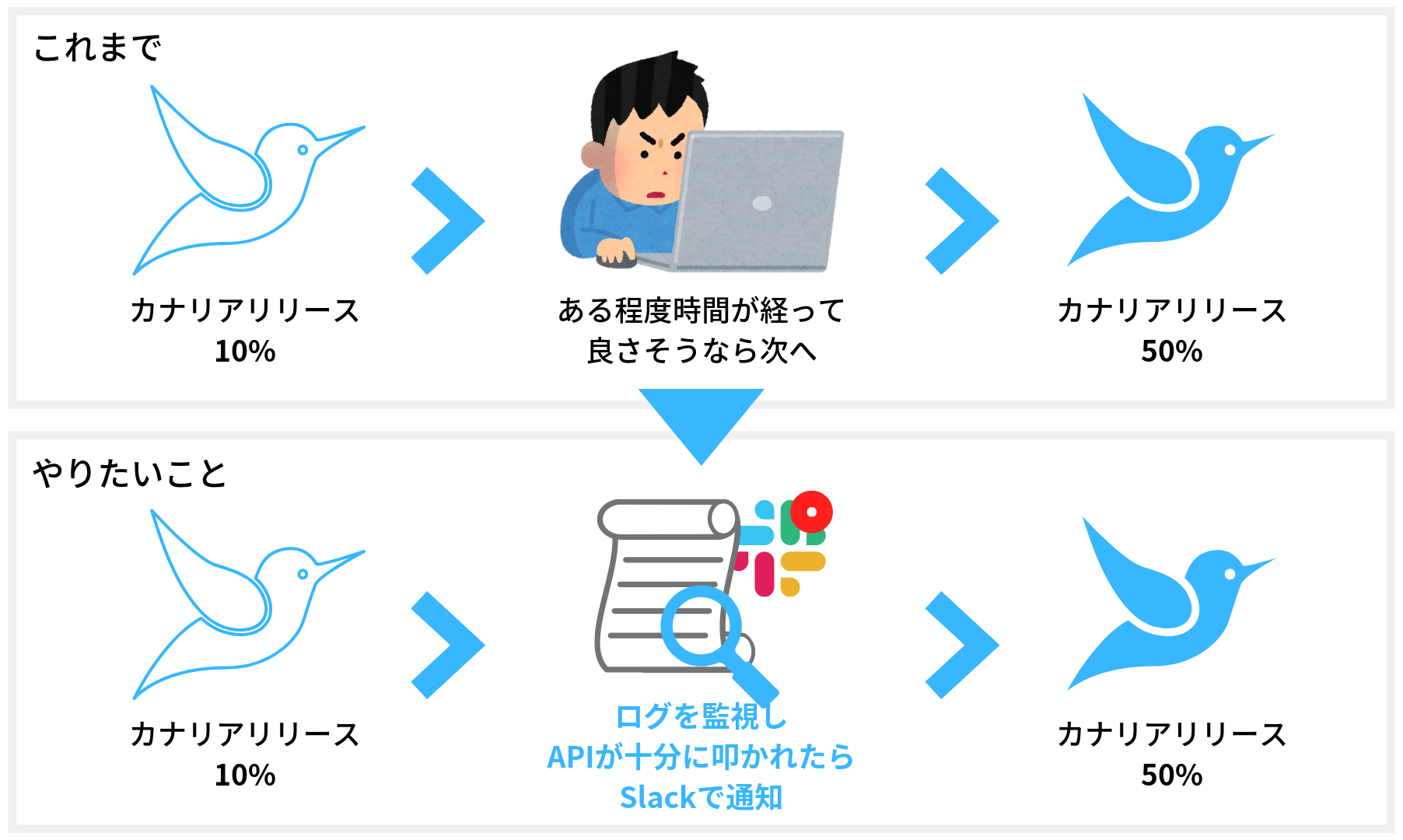
「次のリリースステップに上げる」という操作こそ依然として手動ですが、ツールで「APIが叩かれ(そして成功し)たかどうか」だけでも保証することで人が確認するべきことを1つ減らすことができます。
ツールのユーザが事前に設定しなければならないこととして「どんなリクエストが」「何回成功したら」という2つの変数がありますが、「どんなリクエストが」という部分はアプリケーションの仕様や業務内容によって大きく仕様が左右される部分だと考え、メンターの坂尾さんと都度相談しながら決めました。結果「メソッド」と「パス(URL)」の2つが指定できればいいが、パスにはGlob表現(アスタリスクでワイルドカードが表せるアレ)で指定できるようにする、ということになりました。
この仕様を踏まえた上で、更に「どこからログを取得するか?」ということを決める必要がありました。選択肢としてStackdriver Logging(1次ソース)と、BigQuery(2次ソース)の2つがあったからです。自分は当初クエリの柔軟性とデータの取得時間が探索対象の大きさに左右されにくいことからBigQueryを採用すれば良いと思ったのですが、1次ソースからデータを取得できたほうが全体の構造もシンプルになり、(ツール自体に)障害が起きる可能性も低くなる4という話になり、まずはStackdriver Loggingのほうでパフォーマンス的に要件を満たせるか調査することになりました。
結果、Stackdriver Loggingでも一部のフィールドにインデックスが貼ってあったこともあり、要件を満たすことがわかりました。こうして技術的にはGAE/Goと、Datastore、Stackdriver LoggingのAPIを利用してツールを作成することにしました。
このツールをEnsurerunと名付け、最終日にギリギリ完成させてインターンは終了となりました。ここからは学んだことや悔しかったことを挙げていきたいと思います。
技術的に学んだこと
前の項と重複になる部分もありますが、技術的に学ばせていただいたことを細かく並べてみたいと思います。
- Go1.11.4対応/調査
- Go Modulesについていろいろ
- 多段カナリアリリース
- CircleCI Orbs/Commands/Jobs(Orbs, Jobs, Steps, and Workflows - CircleCI)
- Bashの細かいシンタックス
- Parameter Expansion
${arr[@]}とか${arr[*]}(Arrays (Bash Reference Manual)) あと${#var}とかset -o pipefailとerrexit(pipefailはデフォルトでCircleCIがセットしてくることも知った)<<<(名前わからない)
- Ensurerun
- Stackdriver Monitoring APIとStackdriver Logging APIの違い
- Stackdriver Loggingではどのフィールドにインデックスが貼られるのか(高度なログフィルタ | Stackdriver Logging | Google Cloud)
- BigQueryで正規表現を使ったクエリが実行できること(クエリ リファレンス | BigQuery | Google Cloud)
- Slack Block Kitについて
- gRPCのAny型のデシリアライズ方法(any - GoDoc)
痛感した自分の弱み
遅い
自分はそれぞれのタスクに取り掛かる前、だいたい以下のような時間の見積もりをしていました。
- 多段カナリアリリース: 2日
- Ensurerun: 3日
上記は「もしかしたらこのくらいで終わるかも」という感じではなく、「このくらいあれば絶対に終わるだろう」くらいの感覚でした。
しかし実際にかかった時間をみてみると
- 多段カナリアリリース: 3日
- Ensurerun: 8日
と、どちらも想定よりも時間がかかってしまいました。これは見積りが甘いという話もあるのですが、今回はどちらかというとタスクに時間をかけすぎてしまったのかなと思います。
何に時間がかかってしまったのか考えてみると、とにかく考えたり調べたりする時間が長かったです。「どの技術を使うか」「他にいい方法はないか」から始まり、「どこまでちゃんと設計/リファクタリングするか」「変数名は何が適切か」「もっとシンプルに書けないのか」など細かいところまでいろいろと考えつつ書いていた結果無茶苦茶時間がかかったように思います。

Ensurerunのタスクで実装を始める前に何を考えていたか思い出せる限り書いてみました。8日中3日くらいはこのあたりを調べたり考えたりしていたように思います。
特にEnsurerunに関しては、そんなに大きい規模のプログラムになる予感はありませんでした(し、実際にそこまで大きいものにはなりませんでした)。なので自分としてはできる限り「早く」「シンプルな」プログラムが書けたらいいと思っていましたが、意外とこの2つを両立させるのは難しく、プログラムのシンプルさを追い求めるあまりに時間を掛けすぎたのかもしれない、とも思います。
「どのくらいの技術的な正当性やメンテナビリティを確保すれば合格なのか」という感覚がまだよくわからず、自分の納得感に頼って実装を進めた結果、Ensurerunでは(最低限の機能は満たせたにせよ)やり残したことが多くあり悔しい気持ちのまま会社を去ることになりました。
…といいつつ上記の画像に挙げたようなことは最低限考えたいという気持ちもあり、どうにか同じことを倍速でできるようにならないかなあ… というのが正直なところです。。。
それからリファクタリング周りに関しては、人に見せるコードを(既存コードの機能拡張などではなく)0から書く、ということに意外と慣れていなかったということも感じました。今までのインターン先で行ってきたような、既存のコードがあって、それを変更したり付け足したりするという作業では「周りを見渡して、統一性を崩さない」ということを一番に意識しています。しかしEnsurerunに関してはそれがなかったため個人開発のように好きにリファクタリングをさせていただいたわけですが、人に見せることを意識すると意外といろいろと悩んでしまい、ちょっと時間を取られたかな、と思いました。個人開発での意識が足りていない証拠だなあと思ったのでインターン後ももうちょっとしっかりやっていきたいです。
なんというかまとめると、タスクのスピードアップに関してはまだ「何を効率化すべきか」というのが見極められていない状態です。このあたりは勉強でプログラミングするだけでは身につかない部分だとは思いますが(勉強ならじっくりやるのが一番な気がしています)エンジニアとして身につけたい感覚なので考え続けていきたいです。
進捗報告
正直タスクの消化速度よりも大切なのはこっちな気がします。進捗報告に関してはいつもうまく行かない、というわけではないのですが得意でもなく、今回は微妙にうまく行かなかった部分でもある気がしています。
象徴的だった出来事として最終日の前日にいつまでたってもEnsurerunのPRが出ない自分を心配てくださったメンターの坂尾さんが、ペアプロを申し出てくださったことがありました。これで自分が今やっていることも正確に共有できましたしそのとき考えていたことに関して相談もできたのでとてもありがたかった(しとても楽しかった、ペアプロ初めてだったし)のですが、あとで自分が何をやっているのか数日間もの間共有できていなかったためにチームの方々を不安にさせてしまった結果だと気付きこれは失敗だったなと深く反省しました。
進捗報告が難しい点として、改めて進捗報告するような区切りは意識して作らない限り来ない、というのがあると思います。何かしらに詰まってずっと悩んでいるのならそのタイミングで報告(というか相談)したほうがいいと思いますが、特にそうではなく少しずつでも進んでいる(のに全体としては時間がかかっている)場合に自分は報告の間が開いてしまう傾向があります。なのでそういうときは分報や日報の機会をちゃんと作るのがいいんでしょうね。ATLASチームの場合は朝会があったので、そこでもっと詳しく話しておくべきだったなと思いました。
質問が下手
これはFringe81さんのインターンでもしっかりと指摘されたことだったのですが、まだまだ質問が下手ですね。自分は相談に乗ってくださる方が周りにいるとウキウキで質問/相談してしまう方なのですが、やっぱり相手の時間を奪う行為なのでもうちょっと整理して、言語化をすすめてから質問することを心がけたいです。机にティディベアを置くべきなのか…(質問する前に内容を書き出すとかをもっとしたほうがいいですね)
そのほかいろいろ思ったこと/得たこと
ちょっとまだまとまり切っていないこともありますが、つらつらと書きたいと思います。
インターン生という感覚が薄かった
「やれることをやって」というスタンスだったのがインターン生として新鮮でした。インターン先によってインターン生用の課題があったり、またはそこそこ歯ごたえがあるIssueが用意されていたりと様々ですが、初日にいきなり「何をやりたい?」と聞かれたのは実はちょっと面食らいました。とりあえずやることが決まった後も、メンターさんからのフォローも朝会と数日に一度の1on1面談しか指定されないことに2, 3日は戸惑っていました。
しばらくそこで働くうちに分かったのは「もともとナチュラルに『やれることをやって』という雰囲気だし、インターン生だからという区別もない」ということでした。これはもしかしたらメンターさんやチームの方々の性格もあるのかもしれませんが、それが理解できてからは素直に意見できるようになって楽になりました。
「インターン生として扱われる」のもメリットがあります。短い期間にいろんな部署を体験することができたり、やりがいのある面白い仕事をあてがっていただけることも多いです。
アカツキさんでもある程度は短い期間ということを考慮していただいて、いろいろな方とランチに行かせてもらったりしましたが、開発においては先に書いたようなナチュラルな姿勢で接していただいたことが多かったように思います。次に書く話とも繋がりますが、自分に求められるものがシンプルに「プロダクトへのコミット」になったことは自分にとってはある意味やりやすく、意見もしやすかったり、次にやる仕事を決める際なども決断しやすかったように思います(完全に自分の気持ちの問題なのですが、自分にとっては慣れればとてもモチベーション高く仕事ができる雰囲気だったということです)。
固くない
これはなんというかなかなか言葉にしにくいのですが、「ロジカルなのに固くない」のが良いなと思いました。「チャレンジを推奨している」チームはたくさんありますが、実際に言い出しやすい環境づくりというのはとてもむずかしいことだと思います。自分がいたATLASのチームでは、技術選定のどんな場合でも「ひとつひとつ妥当性を吟味することを厭わず、かつ面白い技術に対して積極的」という印象を持ち、なんというか「のびのびと『やりたいこと』を言えるいい雰囲気だな」と思った記憶があります。自分はこの2つを両立できているというのはなかなかないことなんじゃないか? と思っていて、未だにうまくそれがどういうことなのか言語化できていないのですが… とにかくやりやすかったです。
なんだろう、技術選定において大事にするべきところとそうでないところがちゃんと明確化されているということだったのかな? それとも単に自分の中の判断基準がプロダクト目線になってきたということだろうか? あとプロダクトが新しかったということもあるかも?(曖昧でごめんなさい)
書きながら思いついたことですが、「チャレンジ」ではなく「やりたい」という感情もひとつの理由として拾ってもらえるのが良かったのかもしれません(「チャレンジ」と「やりたいこと」の違いは意識したことがなかったので、もうちょっと考える余地がありそうです)。
またそれに関連して、インターン終了前日の飲みの場で「変に成果を残そうとしすぎ」と笑いながら言われた話があります。この話を思い出したとき、ひとつ心当たりがありました。自分は今回CI周りを重点的に触りましたが、Bashのシンタックスの難解さから「シェルスクリプトはFishで書いたほうがいいのでは?」と「密かに」思っていました。しかしそのことを誰かに提案することはありませんでした。
ここでは「本当にFishでシェルスクリプトを書くべきなのか」という部分については触れません。とにかく自分はこのことを胸に留めたままインターンを終えてしまいました。その意図としては、「どうせ自分は数週間でいなくなり、自分が書いたコードもすぐに自分以外の誰かがメンテしなければならなくなる」という理由からでした。
それ自体は理にかなっていると思います。チームの中で普段からFishを使っているのは自分だけでしたし、何より既存のコードの大部分はBashで書かれていて、統一性も大切なメンテナビリティだと思います。しかし「変に成果を残そうとしすぎ」というのは、つまり「もっとやりたいことをやっていいよ」ということだったのではないかとインターンを終えた後になって思いました。この変更は確かに先述のようなデメリットもありますが、自分の中ではチーム全体にとって長期的にはメンテナビリティを上げるための意見でした。ならばもうちょっと「やりたいこと」として全面に押し出して提案だけしてみても良かったのかな、と思いました。
いろいろと書きましたが、「ロジカルだけど固くない」のが心地よかった話でした。
「どれだけちゃんとやるのか」の感覚を学んでいきたい
ちょっと前述もしましたが、やっぱり「どれだけちゃんとやるのか」というのが意外な「業務でしか学べない点」だったなと思いました。個人開発だと自分は結構プロダクトを早く完成させることよりも、今学びたいことを気が済むまで学びつつ欲望の赴くままにコーディングするのでなかなかそういうことは考えません。ただこのあたりのことは授業をしっかりと受けチーム開発にもちゃんと取り組めば学べそうな気がしているので、意識していきたいと思っています。
「素早く必要十分なコードを考える」力ですね。
結局何を学んだの?
技術的に学んだことは技術的に学んだことで書いたので、ここではそれ以外をまとめると、
いろいろと自分がこれから気をつけていかなければならない箇所を認識できた1ヶ月だったように思います。
- 「ちゃんとやる部分」を見極めて最小限のコードを早く作り出せるようになりたい
- 「本当に必要なもの」をロジカルに考える癖が必要
- 進捗報告する癖
- チームメイトの気持ちを考える
特に「本当に必要なものを考える」感覚が少しでも身についたかな、と思いました。
またとてもモチベーション高く仕事ができるチームの雰囲気だったので、今後自分の振る舞いを考える上で参考にしたいなと思いました。
まとめ
インターンはもう行かなくていいかなと思っていたのですが、最後にアカツキさんに行けてとても良かったと思いました。技術的にも仕事をする上での振る舞いに関してもとても考えさせられることが多かった1ヶ月で、自分にとって大きな跡が残るようなインターン期間だったと思います。
こんな自分を受け入れ成長の機会をくださった坂尾さん、田中さんにはとても感謝しています。本当にありがとうございました!
このエントリーがどなたかの参考になれば幸いです。
-
「GAEによってトリガされたCloud BuildでのGoアプリケーションのビルドではgo.sumが読み込まれるのか?」というのが知りたかった情報でした。読み込まれていなかった場合Cloud Build上のGoのバージョンとローカルのGoのバージョンが違っていてもビルドが通ると考えられます。 ↩︎
-
後述もしますがGAEはすべての環境で一斉にGoのバージョンを変更するわけではなくカナリアリリースのようなことをしているため、すべての環境で同じ状況ではありません。 ↩︎
-
一応「最新のマイナーバージョンを使用する」という記述はありました。Go 1.11 Runtime Environment | App Engine standard environment for Go 1.11 docs | Google Cloud ↩︎
-
単純に関わるコンポーネントが増えれば、どれかに障害が起きる可能性が高まるという話です。参考: ルッサーの法則 - Wikipedia ↩︎