[Go言語] お前の文字列引数のドキュメントは多分間違っている
これば Go2 Advent Calendar 2019 - Qiita の16日目の記事です。
この記事は会津大学 Zli BigLT2019 #biglt2019_aizu で発表した"UTF-8 依存の Go コードとは?“の内容をまとめ直したものです。
Go では文字列操作を比較的簡単に行うことができますが、実はその挙動をドキュメントするという作業は意外といろいろな落とし穴があり、気を遣う作業です。今回は「文字列を受け取る関数」を外部に公開するということを前提として、正しくドキュメントを書くための確認事項をまとめたいと思います。
string 型の文字コードって?
例えば
func ToLower(s string) string
という関数があったとき、s の文字コードは何でしょうか?
答えは「未定義」です。要するに 「string 型に入る文字コードは決まってないよ」 ということですね。
ドキュメントに明示的に書いてあります。
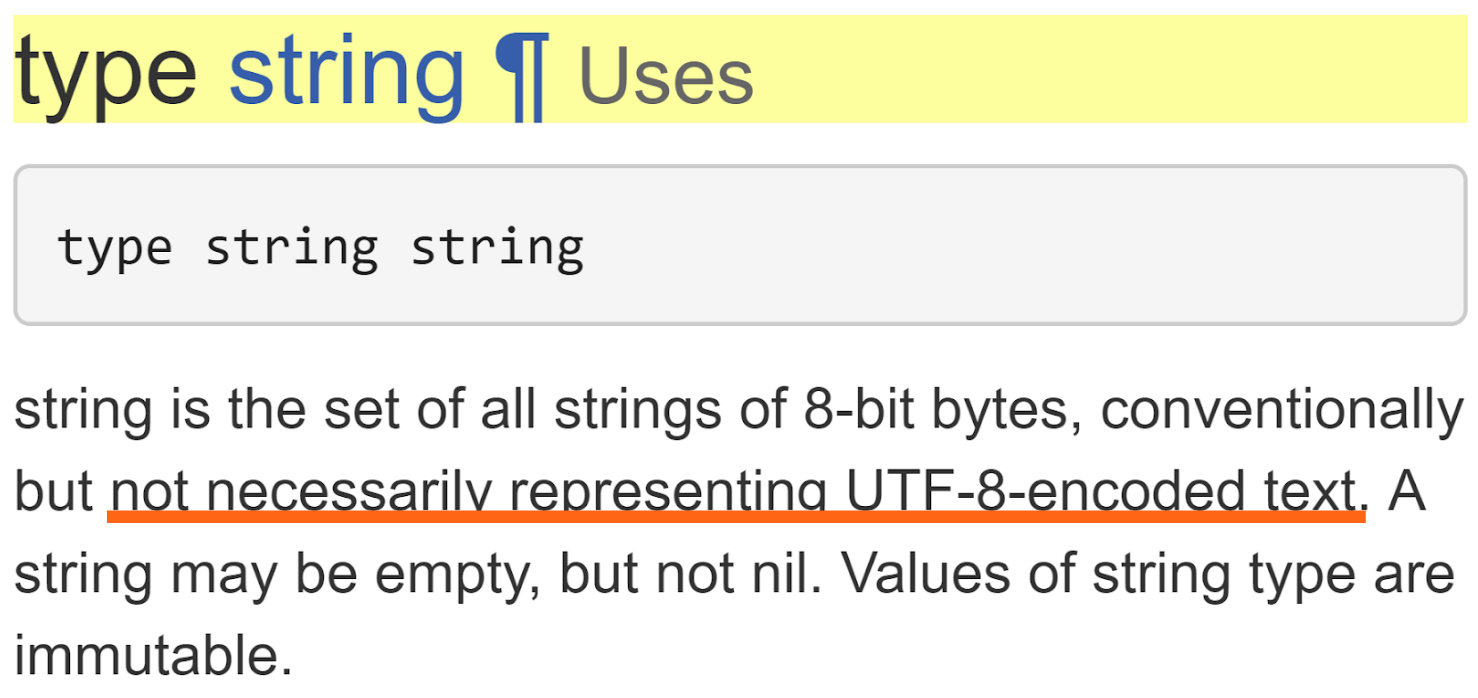
「必ずしも UTF-8 の文字列である必要はない」
よって関数が string 型の文字列を受け取り、その挙動が文字コード依存の場合、ドキュメントには対応する文字コードを明示しなければならないと言えます。
もちろんこれは []byte や []rune にも同じことが言えます([]rune も UTF-8 限定の型ではありません)。
「UTF-8 依存のコード」とは何か
前項では「string 型の文字コードを明示する必要性」について話しましたが、最もありがちなミスは「引数が UTF-8 前提の関数なのに、ドキュメントにはそう書いていない」場合だと思います(そもそも他の文字コードに対応することを意識していれば、ドキュメントに書くのを忘れることもないでしょう)。
そこでここでは「どういうコードが UTF-8 依存なのか(非依存なのか)」を確認していこうと思います。
以下、例に出てくる変数
str→string型bts→[]byte型rns→[]rune型
とします。
キャスト
UTF-8 依存の例
string(rns)[]byte(rns)[]rune(str)[]rune(bts)
UTF-8 非依存の例
string(bts)[]byte(str)
string、[]byte、[]rune の相互キャストです。基本的に []rune が絡んでいると UTF-8 依存のコードになってしまいます。
ループ/インデックス
UTF-8 依存の例
for _, c := range str {
_ = c
}
for i := range str {
_ = str[i]
}
これらは UTF-8 依存のコードです。 c には1文字の rune が、 i には1文字の始まりに該当するインデックスが入ります(i は連続した値でない可能性があります)。
詳しく: String と Rune — プログラミング言語 Go | text.Baldanders.info
UTF-8 非依存の例
for i := 0; i < len(str); i++ {
_ = str[i]
}
i := range str が UTF-8 依存だったのに比べて、こちらは非依存のコードになります。この場合必ず i は連続した値を取り、 str[i] は単に str の i 番目のバイトを表すでしょう。
その他
len()
len(str) はUTF-8 非依存のコードです。これは str の文字数ではなくバイト数を返すためです。
strings.*
標準ライブラリの strings パッケージは冒頭に UTF-8 のためのパッケージであることが明示されています。
なので strings.* 関数を利用している場合、基本的に UTF-8 依存のコードになると思ったほうがいいでしょう。
bytes.Index()
もちろん bytes パッケージは UTF-8 依存なんてことはないのですが、ちょっと罠だなと思うのは bytes.Index() 等を用いて文字列の比較/検索を行う場合です。
例えば
bytes.Index([]byte(str1), []byte(str2))
このコードは str1 、 str2 が UTF-8 だった場合正しく動作しますが、Shift-JIS の場合は予期しない挙動を起こす可能性があります。
例えば Shift-JIS で 表 という漢字のバイト列は 0x95 0x5C ですが、\(バックスラッシュ)は 0x5C となっています。
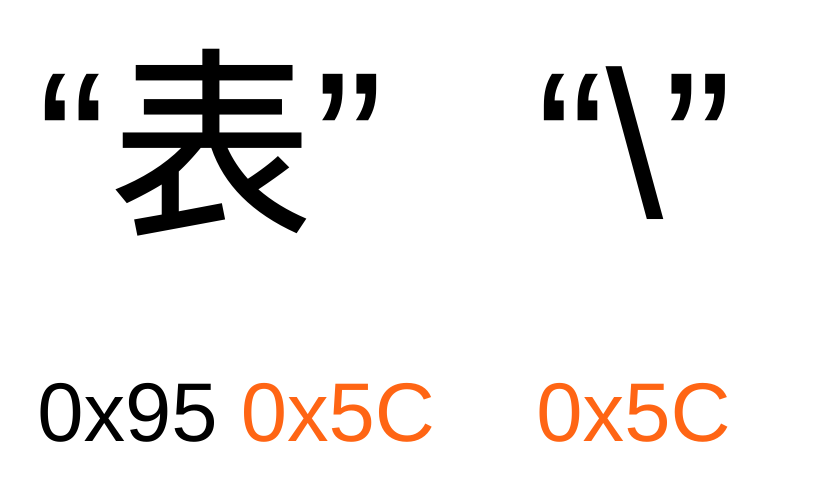
なのでこれらの文字をそれぞれ str1 、 str2 としたとき、 bytes.Index([]byte{0x95, 0x5C}, []byte{0x5C}) が行われることになり、 Shift-JIS 上では別々の文字であるにも関わらずマッチしてしまいます。
なぜ UTF-8 で同様の問題が起こらないかと言うと、UTF-8 では「文字の1バイト目と2バイト目以降の取りうる範囲は異なる」という規則があるからです。

https://en.wikipedia.org/wiki/UTF-8#Description
よってこのようなコードは一部の文字コードに依存していると言えます。
UTF-8 依存のコードを作り出す(仮)
「無意識に書きやすい UTF-8 依存のコード」について説明しました。では上記のようなコードを書いていたら 「引数は UTF-8 です」とドキュメントに書いておけばそれだけでいいのでしょうか?
実は逆に「正しく UTF-8 対応をするために気をつけなければならないこと」というのがいくつかあります。これらを意識せず「 UTF-8 なら対応している」とドキュメントに書くことは、それは Better ではありますが、完全に正しいとも言えません。
以下に3つドキュメントを書く上で気をつけなければならない UTF-8 の概念を記します。
ASCII 依存かどうか?
例えば
// ParseDigit は r を数字としてパースします。r の文字コードは UTF-8 です。
func ParseDigit(r rune) int {
return int(r - 48)
}
このような関数を定義したとしましょう。この関数は以下のように動作します。
fmt.Println(ParseDigit('3')) // => 3
この関数の問題は、ドキュメントに「ASCII Number にしか動作しないこと」が明記されていない点です。