Stripe SSoT から CQRS へ
この記事は JP_Stripes Advent Calendar 2024(シリーズ2) 21 日目の記事です
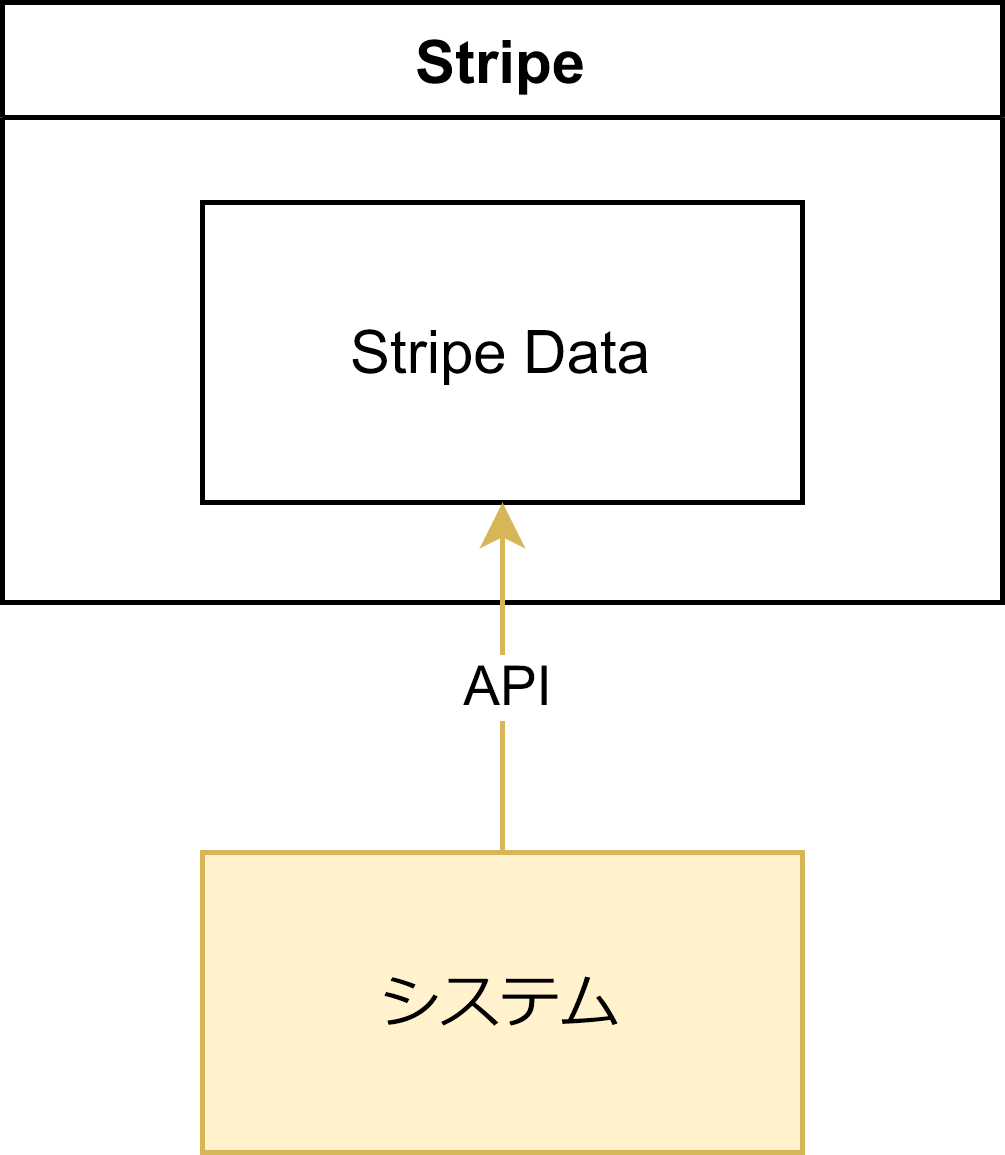
Stripe を使ったシステムを作るとき、上図のような「Stripe だけに購入可否のデータを持たせ、ユーザーからのリクエスト都度 API 経由で取得する」シンプルな方法を取る場合も多いと思います。
なぜこの方法が採用されるかというと、
- 「支払いが完了したのに購入結果がサイトに反映されない」等の不整合が起きない
という明確なメリットがあるためだと思います。
しかしデメリットとして
- Stripe の metadata に頼りがち
- 1ユーザーに大量の購入が紐づいているなど、一部のユースケースでパフォーマンスが問題になることがある
という点も存在し、別の方法を取る必要がある場合もあります。
このときに、「不整合が起きない」というメリットを捨てずに、デメリットを解消したより良いアーキテクチャがあるかどうか、という思考実験が今回のお話になります。
そもそもなぜ不整合が起きないのか
なぜ先のアーキテクチャでは不整合が起きないのか、と考えると、
不整合とはデータのコピーがあったとき、その2つのデータのずれのことを言うので、先のアーキテクチャではそもそもデータのコピーが存在しない(Stripe の購入の可否のデータは Stripe 側にしかない)ので、不整合が起きようがない
という結論に達します。
このようなアーキテクチャは SSoT(Single Source of Truth)とも呼ばれます。SSoT では、「根拠となるデータ(Source of Truth) が常に一つであり、はっきりしている(そして必要に応じて自動的に参照される)」場合であれば、SSoT と言えます。しかし SSoT では絶対にデータ(根拠)のコピーを作っていけないわけではありません。いわゆるデータのキャッシュは許されます1。なぜならキャッシュとキャッシュ元で不整合が起きた場合、正解となるのは常にキャッシュ元であるためです。
今後この記事では、そのように 「正解となる(なりうる)」ことを「根拠である」 と呼びます。SSoT とは「根拠が一つであること」と言えます。
問題は「Stripe だけにデータがあるかどうか」というより「Stripe 由来のデータを吹き飛ばせるかどうか」
さて、一発目の図に戻ります。
このアーキテクチャで根拠となっている箇所を□で囲むと
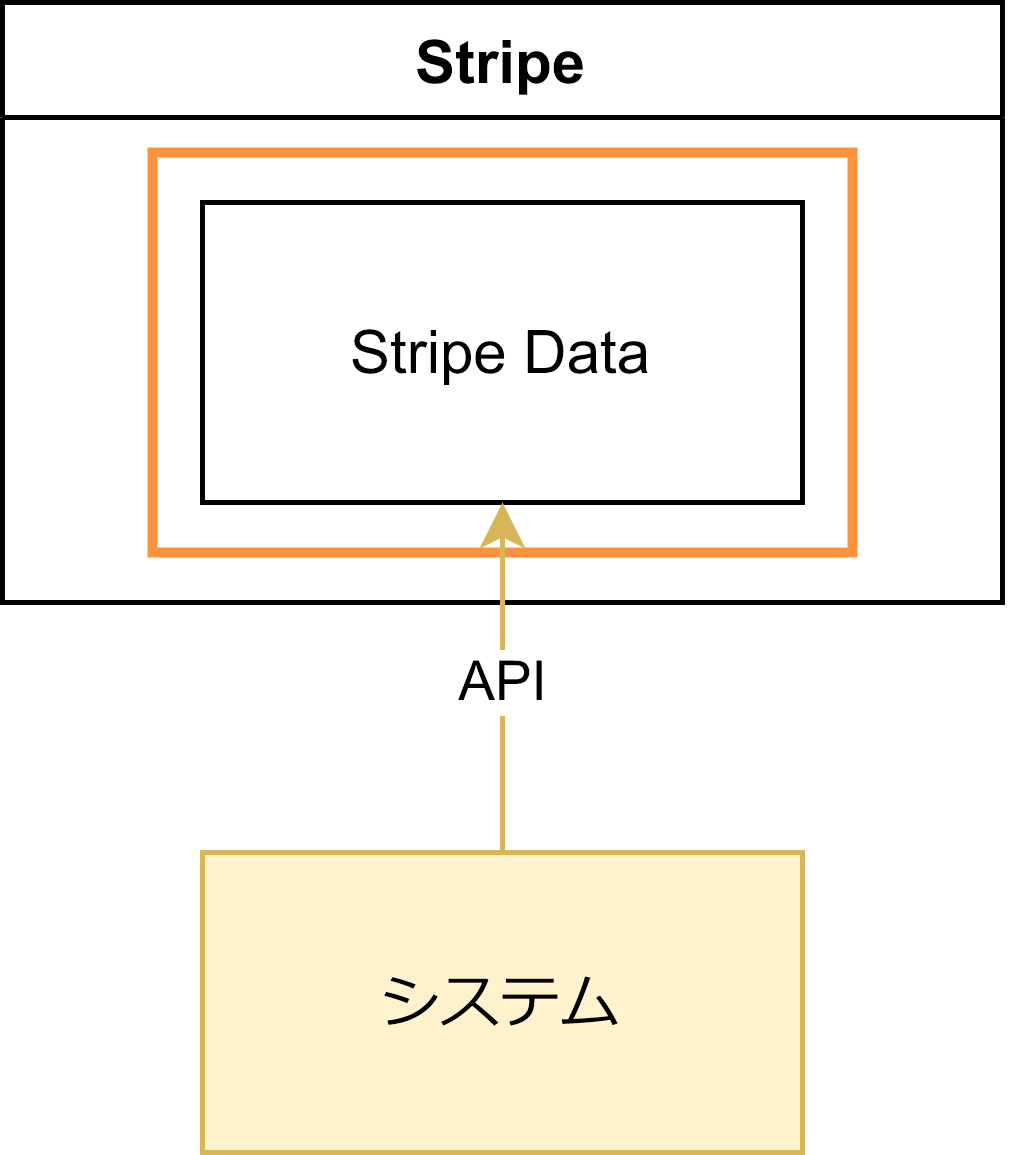
このように「Stripe Data」の部分だけなので、SSoT になっているということですね。
しかしこのままではパフォーマンスに問題があるとします。ここで真っ先に考えられるのは、Stripe Data のキャッシュを DB に作ることです。
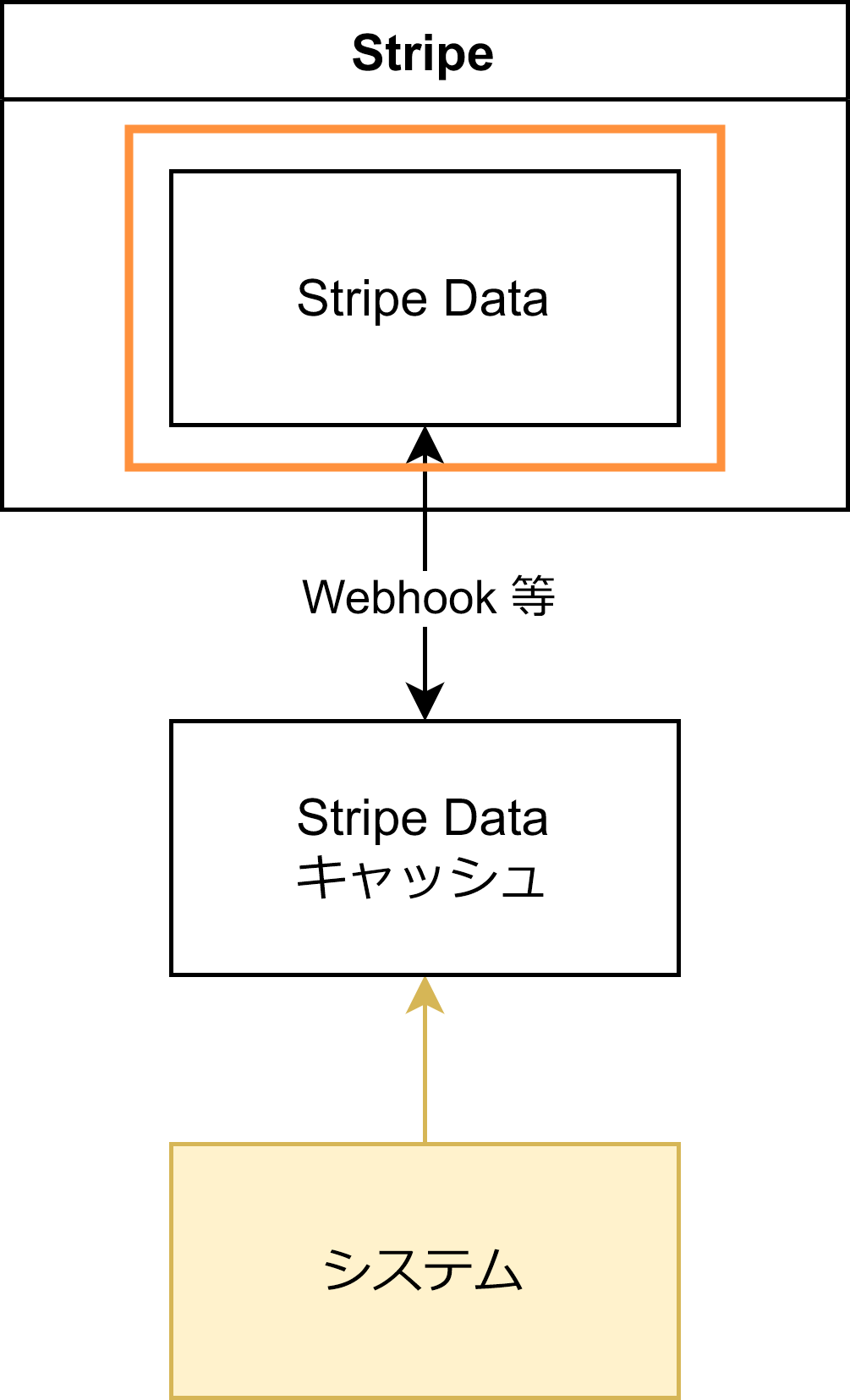
この場合でも、根拠となっている箇所は1つです。
更に、せっかく DB を使うことになったので、今まで Stripe の metadata に入れていた購入の詳細情報を、DB 側に入れてしまうことにしました。
また、Stripe のデータ形式そのままだと無駄も多く、JSON 形式だと RDBMS にそぐわないので、Orders テーブルとしてビジネスに適したスキーマのテーブルに変更しました。
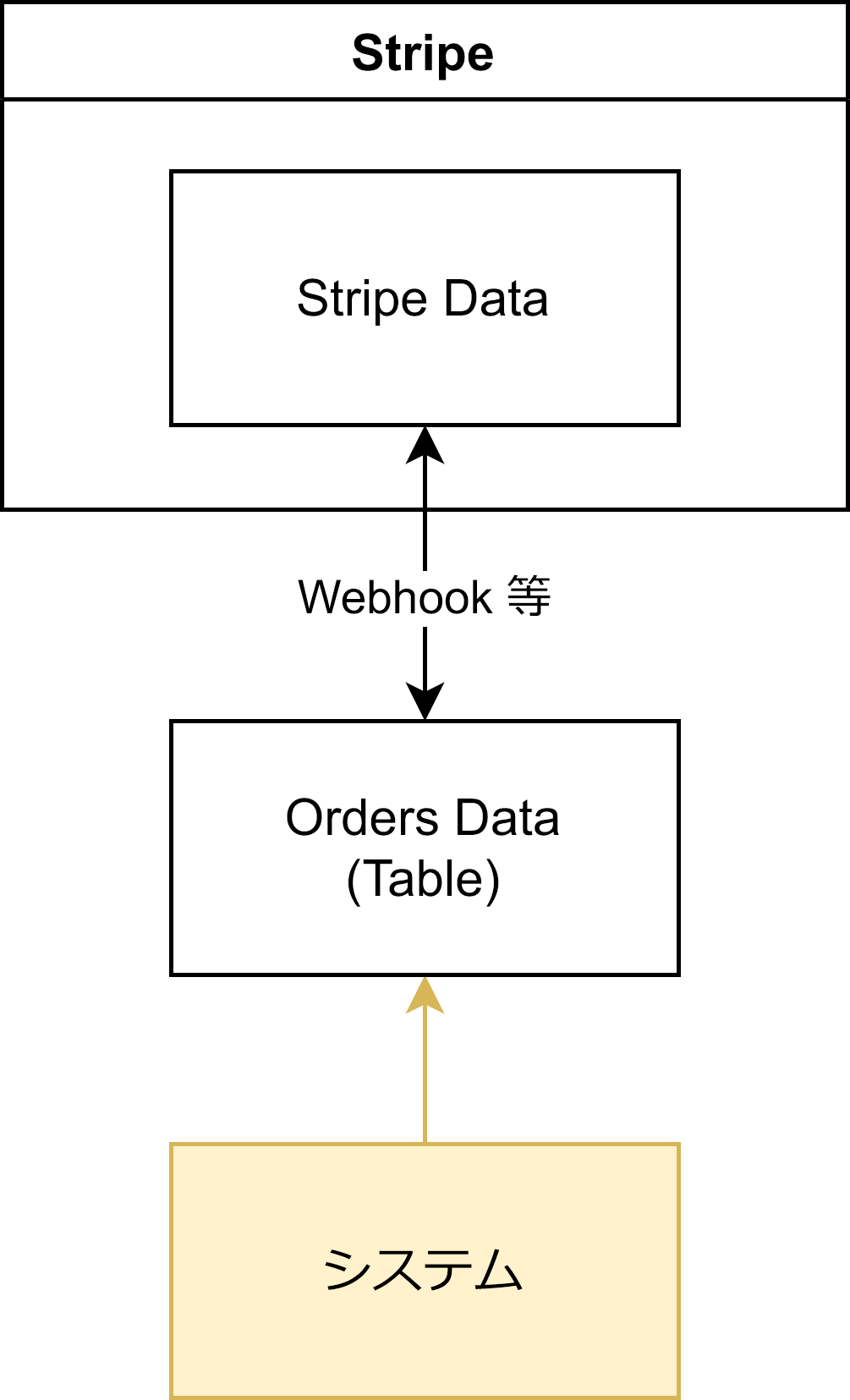
この場合でも、根拠となる箇所は1つのままでしょうか?
Orders テーブルには Stripe データ以外のデータが混じってしまっているため、「Stripe Data のビュー」とは言えなくなってしまいました。この Stripe データ以外のデータに関しては、ここが唯一の「根拠」となるため、根拠となる箇所は Stripe Data と Orders テーブルの2つとなります。
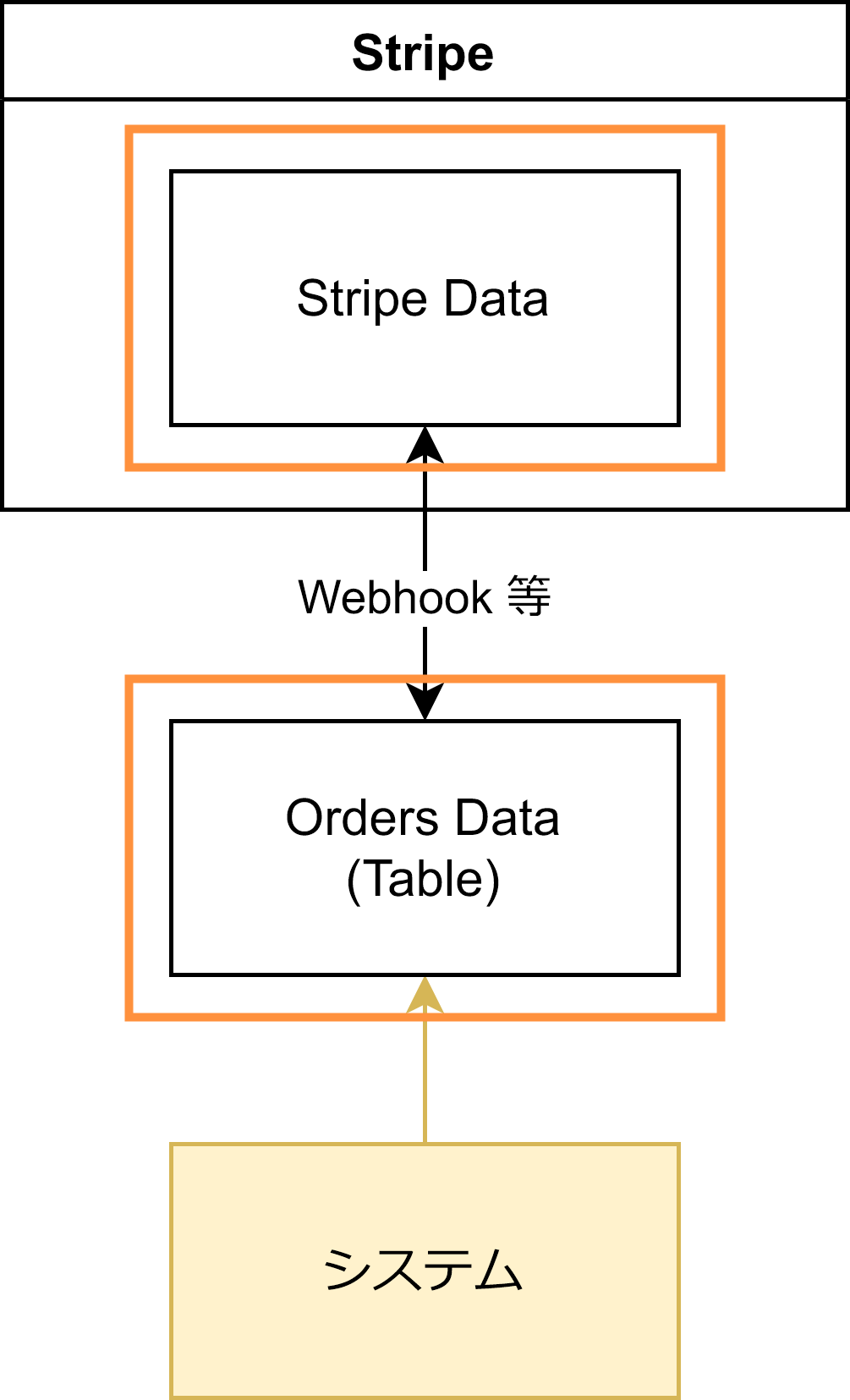
もちろん Orders テーブルの中でも「Stripe 由来のデータは Stripe 側が正解(根拠)」ですし、それ以外の場合はそのテーブルの内容が正解と言えますが、それを一件一件チェックするための突合処理が必要になり、単純に「キャッシュまるごと吹き飛ばす」みたいなことは不可能になってしまっています。
根拠となる箇所を分離し、減らす
先のアーキテクチャで何が問題なのでしょうか。SSoT アーキテクチャの利点に立ち返りましょう。SSoT アーキテクチャでは、そもそもデータのコピーが(高々キャッシュしか)存在せず、不整合が起きないのでした。しかし Orders テーブルには Stripe 以外のデータが入り込み、不整合が発生しても単純に吹き飛ばして不整合を解消することはできません。
簡単に不整合を解消できるようにするには、「根拠となる」箇所を絞り、「根拠となる」箇所以外のコピーは簡単に吹き飛ばせるようにすることが重要です。2つ例示します:
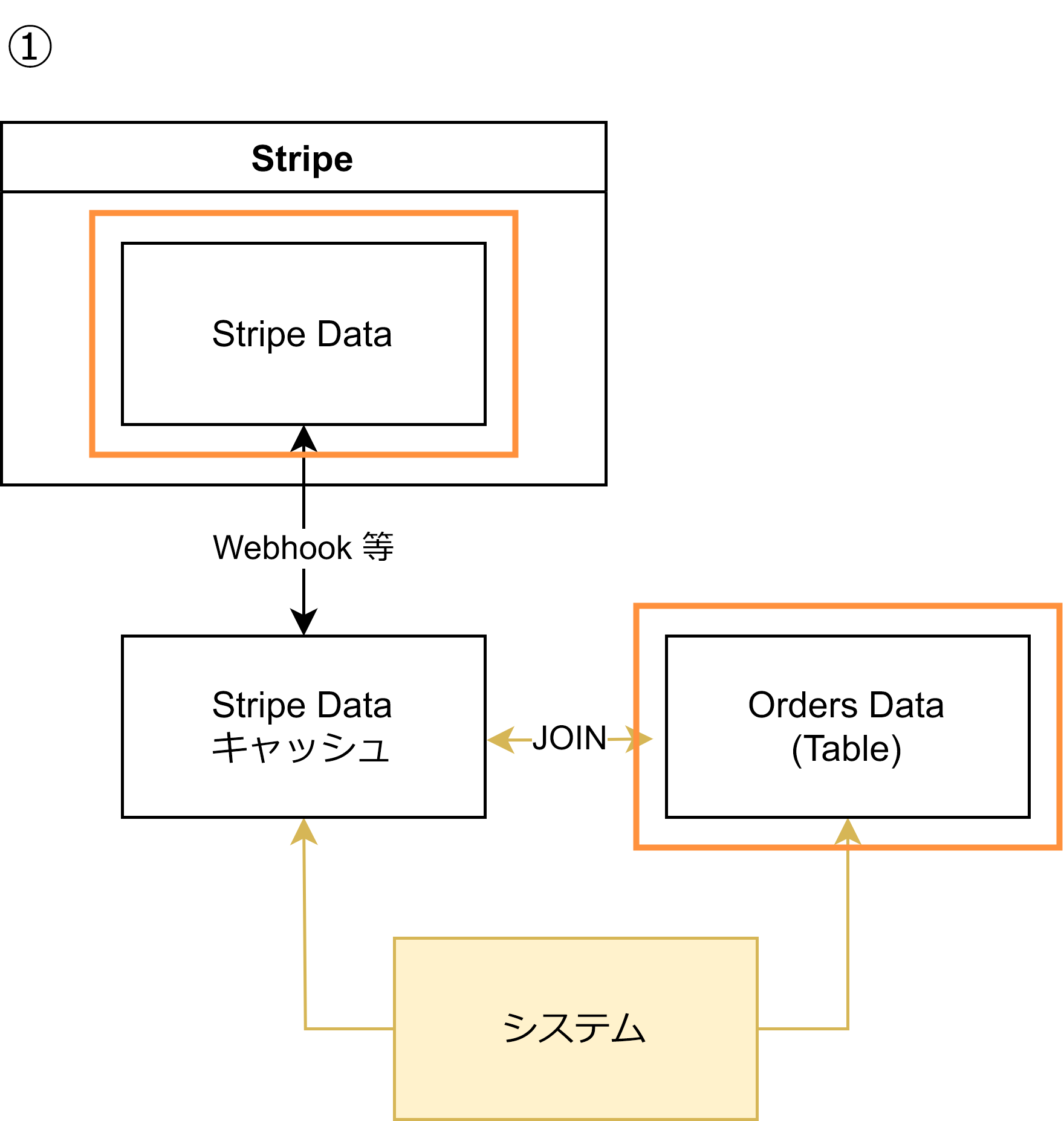
上記の図では、Stripe からのデータは Orders Table から「Stripe Data キャッシュ」に分離されました。Stripe Data キャッシュはキャッシュなので吹き飛ばすことができ、定期的に更新することで簡単に不整合を解消することができます。依然として根拠となる箇所が2つありますが、Stripe のデータのみに着目すると、根拠は Stripe 1点に集約されているため、管理が容易です。
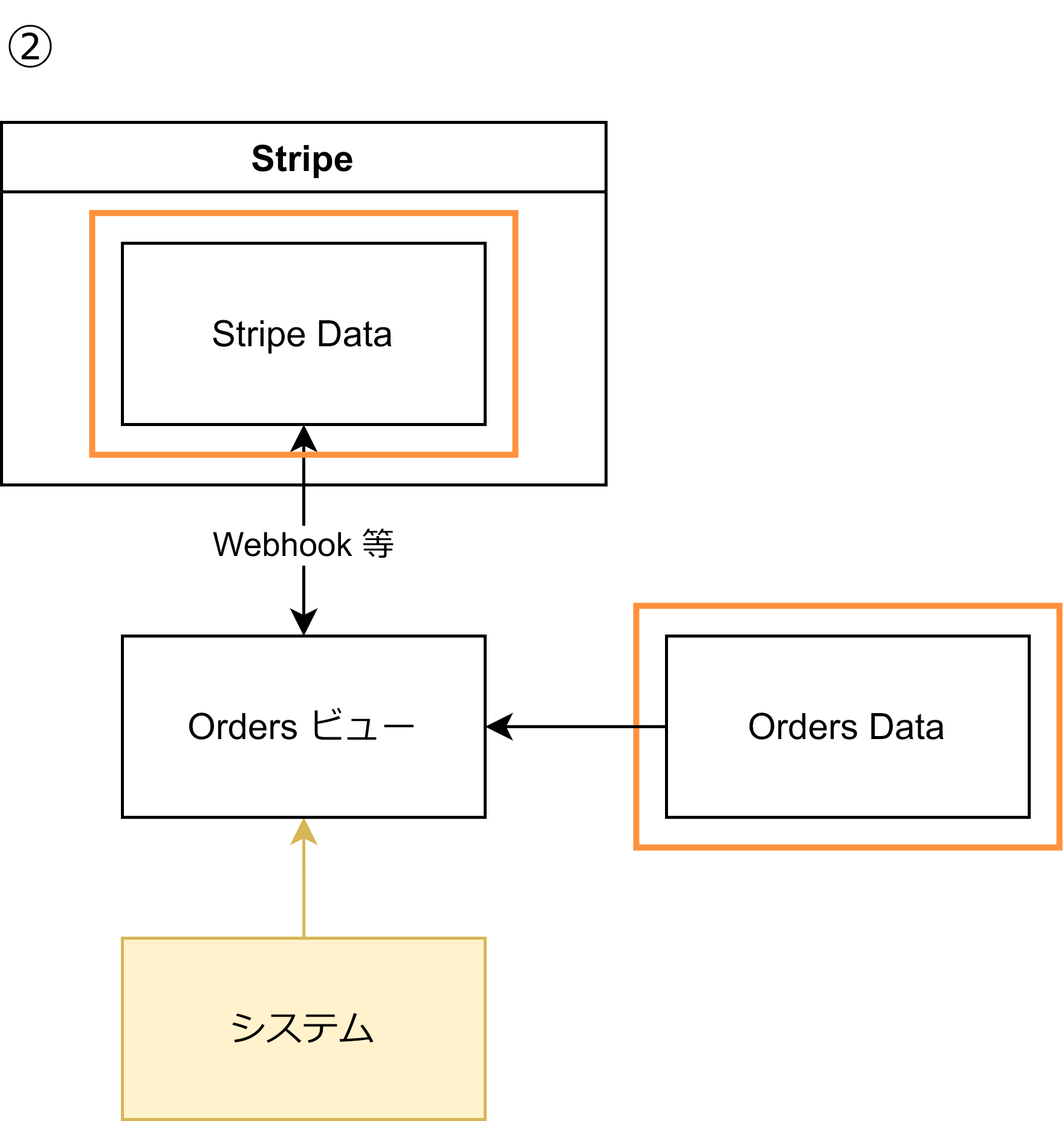
2例目では、同様に Stripe のデータを Orders テーブルから分離しています。1例目と異なるのは、Stripe のデータと Orders のデータをクエリ用に統合したビューとして作成していることです。ビューはキャッシュと同様にそれ自体に UPDATE を直接加えることはなく、また理想的には吹き飛ばすことも可能です。(このように「クエリ用のモデル」を特別に持つことを CQRS と呼びます2)
上記の2例のように、根拠となる箇所をデータの要素ごとに一つにし、それ以外の箇所はキャッシュやビューに留め吹き飛ばせるような構成にしておくことで、不整合が起きづらく、また簡単に解消できるアーキテクチャを設計することができるはずです。
Our Story
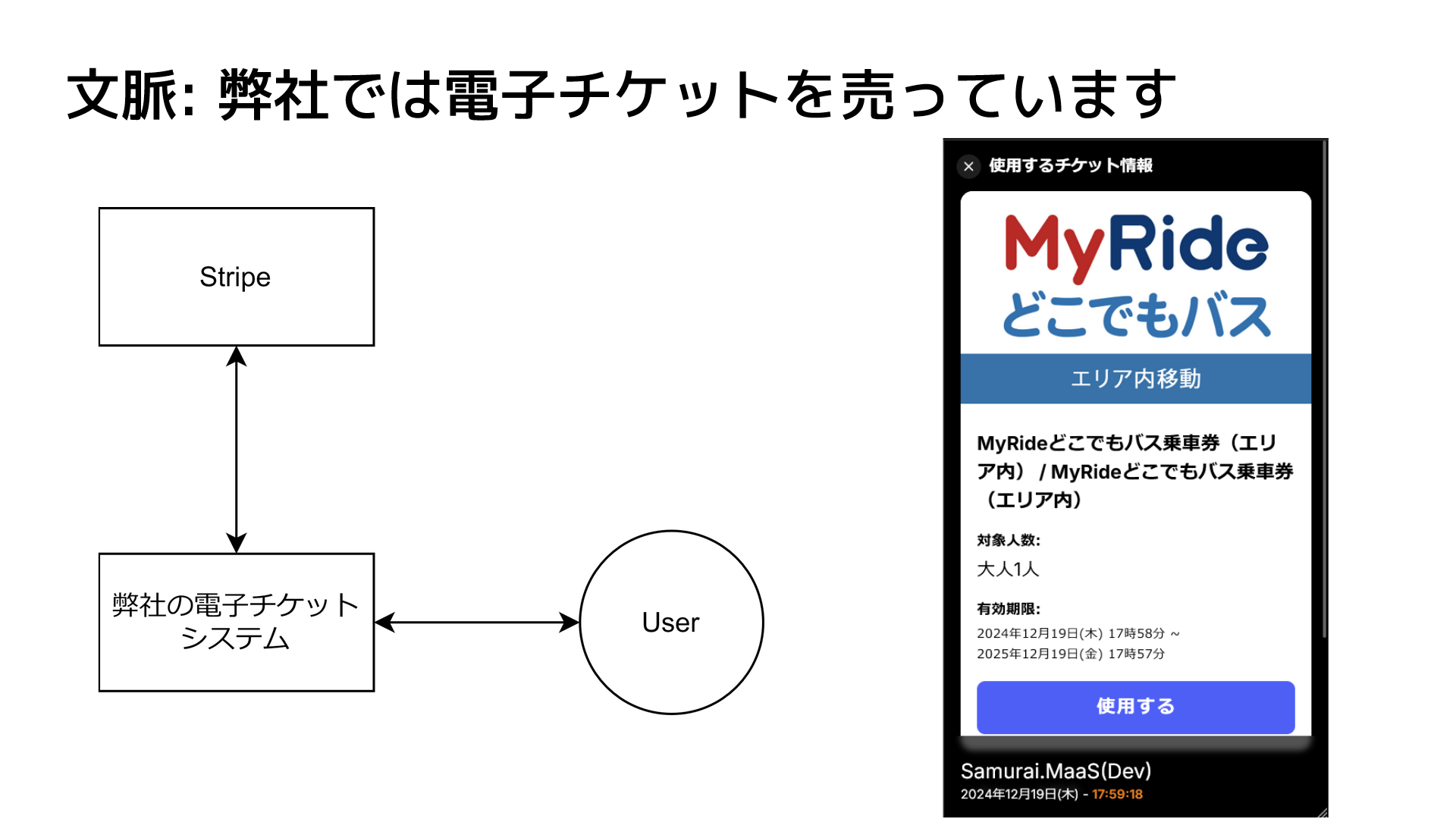
弊社のシステムでは、初期「ユーザーが購入したチケットのリスト」のデータを Stripe から都度取得していました(SSoT)。
しかしその後パフォーマンスの理由により、Stripe からの都度取得を辞める必要が出てきました。そのとき選択した手法が「ビジネスロジックのモデルを素直に表現した DB Schema に移行する」方法でした。
その結果、「Stripe を正解とするべきデータ」とビジネスロジックのデータが混在して一つのテーブルに保存されることとなりました。
その後システムは拡張を繰り返し、例えば Purchase Table の status フィールドには「処理中」「完了」等に加えて「未承認」「承認済み」のような私達独自の状態も入るようになりました。
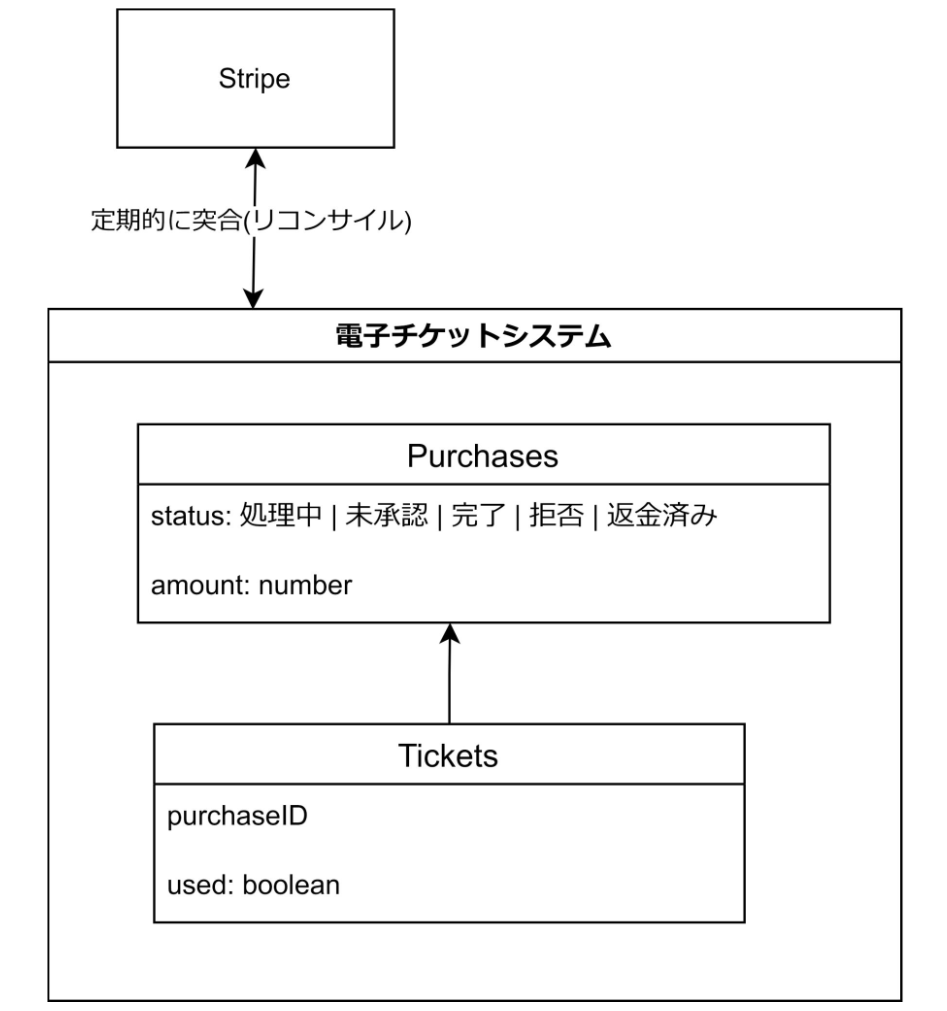
が、その後の突合処理(リコンサイル)の実装/運用に苦労し、現在他のアーキテクチャも検討しています。
よりよいアーキテクチャとしては、例えば下記のような構成もあったのではないかと考えています。
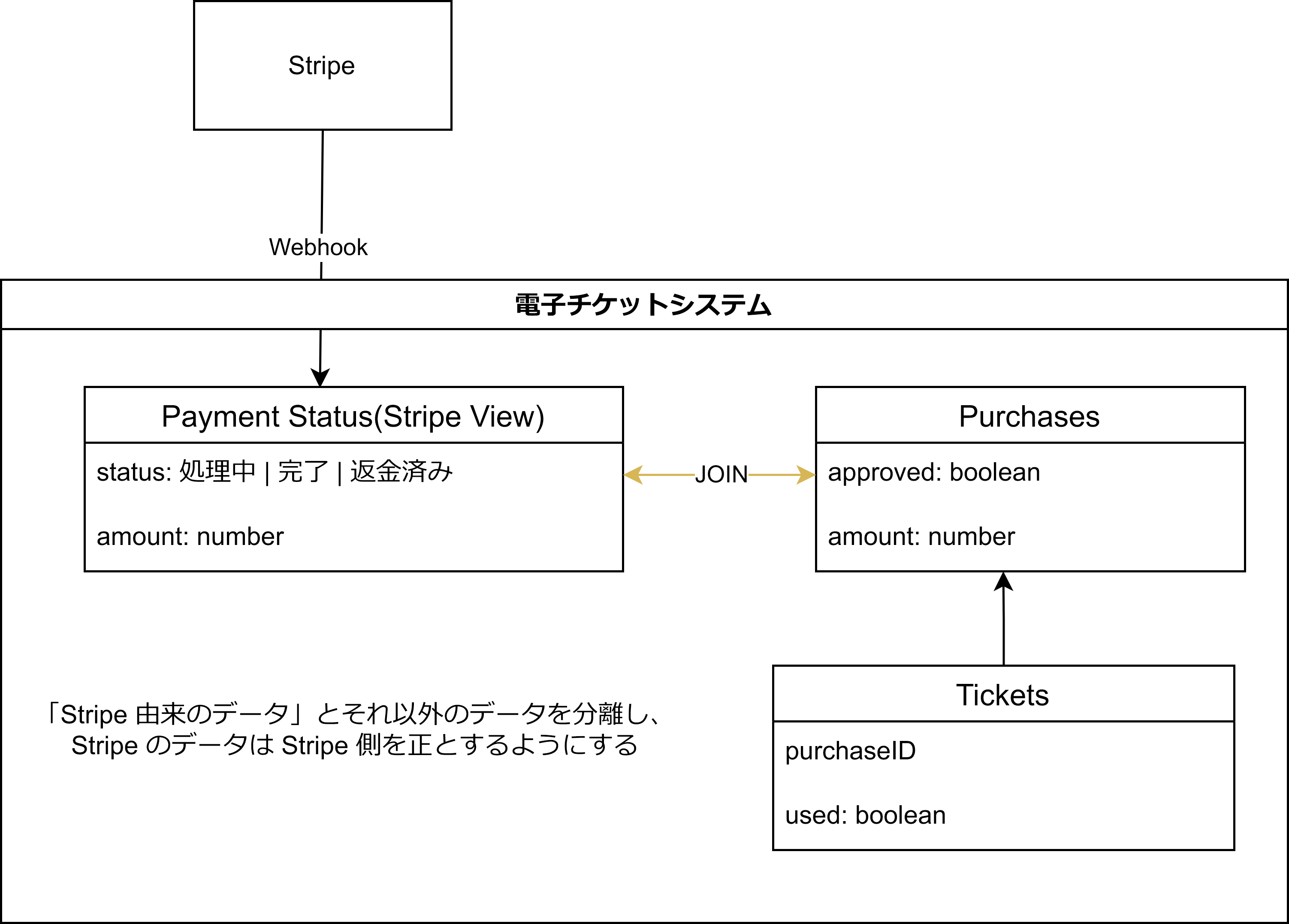
Stripe を根拠とするべきデータについては、Purchases テーブルから切り離したビューとして取り扱い、クエリ時には Purchases テーブルと JOIN して取得するような構成です。
このような構成にしておくことで、パフォーマンスを犠牲にすることなく、不整合が起きづらく、いざとなればビューテーブルごと吹き飛ばせるような構成も可能かと考えています。
まとめ
Stripe から購入データを毎回取得するような方法が使えない場合でも、CQRS のビューを用いて極力不整合が起きづらいアーキテクチャを作成できるのではないかという考察をしました。
まだ実践できているわけではないので、感想や実際にこうしているよという事例等コメント頂けたらとても勉強になるかと思います。
最後に、この記事を書くきっかけとなったリプをくださり、また LT の機会をくださった @hidetaka さん、Stripe CQRS について具体的なイメージが湧く分かりやすい説明をつけてくださった @yoshii0110さん、その他情報をくださった皆様に深く感謝申し上げます。ありがとうございました!
-
正直に言えば、ここは私の解釈です。Wikipedia によると、データのコピーができた時点で SSoT というよりは CQRS になるという記述があります。しかし、キャッシュとはそもそもアーキテクチャとはレイヤが違う概念であり、「アーキテクチャと言うより最適化の範囲」というのが私の意見です。また、Martin Fowler さんによると CQRS とは「異なる複数のモデルを扱うこと」です。
At its heart is the notion that you can use a different model to update information than the model you use to read information.
キャッシュが「新たなモデル」と言えるかというと怪しく、キャッシュを作れば SSoT から CQRS になるとは考えづらいため、ここでは SSoT でも単純なキャッシュによるデータのコピーのみは許されることとしています。 ↩︎
-
この段落以降で利用している「ビュー」という言葉は、「データ指向アプリケーションデザイン」の CQRS についての説明からお借りした言葉です。「データを書き込む(ための)形式」に対して、「データを読み込む(ための)形式」について「ビュー」と表現しています。 ↩︎